
This blog post focuses on new features and improvements. For a comprehensive list, including bug fixes, please see the release notes.
Introducing the template to fine-tune Llama 3.1
Llama 3.1 is a collection of pre-trained and instruction-tuned large language models (LLMs) developed by Meta AI. It’s known for its open-source nature and impressive capabilities, such as being optimized for multilingual dialogue use cases, extended context length of 128K, advanced tool usage, and improved reasoning capabilities.
It is available in three model sizes:
- 405 billion parameters: The flagship foundation model designed to push the boundaries of AI capabilities.
- 70 billion parameters: A highly performant model that supports a wide range of use cases.
- 8 billion parameters: A lightweight, ultra-fast model that retains many of the advanced features of its larger counterpart, which makes it highly capable.
At Clarifai, we offer the 8 billion parameter version of Llama 3.1, which you can fine-tune using the Llama 3.1 training template within the Platform UI for extended context, instruction-following, or applications such as text generation and text classification tasks. We converted it into the Hugging Face Transformers format to enhance its compatibility with our platform and pipelines, ease its consumption, and optimize its deployment in various environments.
To get the most out of the Llama 3.1 8B model, we also quantized it using the GPTQ quantization method. Additionally, we employed the LoRA (Low-Rank Adaptation) method to achieve efficient and fast fine-tuning of the pre-trained Llama 3.1 8B model.
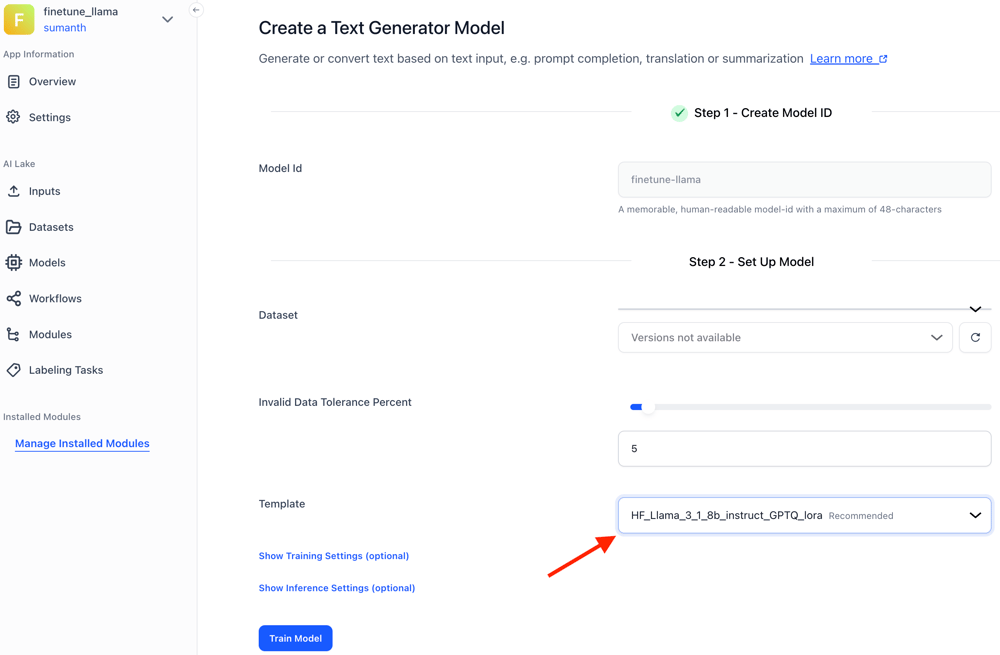
Fine-tuning Llama 3.1 is easy: Start by creating your Clarifai app and uploading the data you want to fine-tune. Next, add a new model within your app, and select the “Text-Generator” model type. Choose your uploaded data, customize the fine-tuning parameters, and train the model. You can even evaluate the model directly within the UI once the training is done.
Follow this guide to fine-tune the Llama 3.1 8b instruct model with your own data.
Published new models
Clarifai-hosted models are the ones we host within our Clarifai Cloud. Wrapped models are those hosted externally, but we deploy them on our platform using their third-party API keys
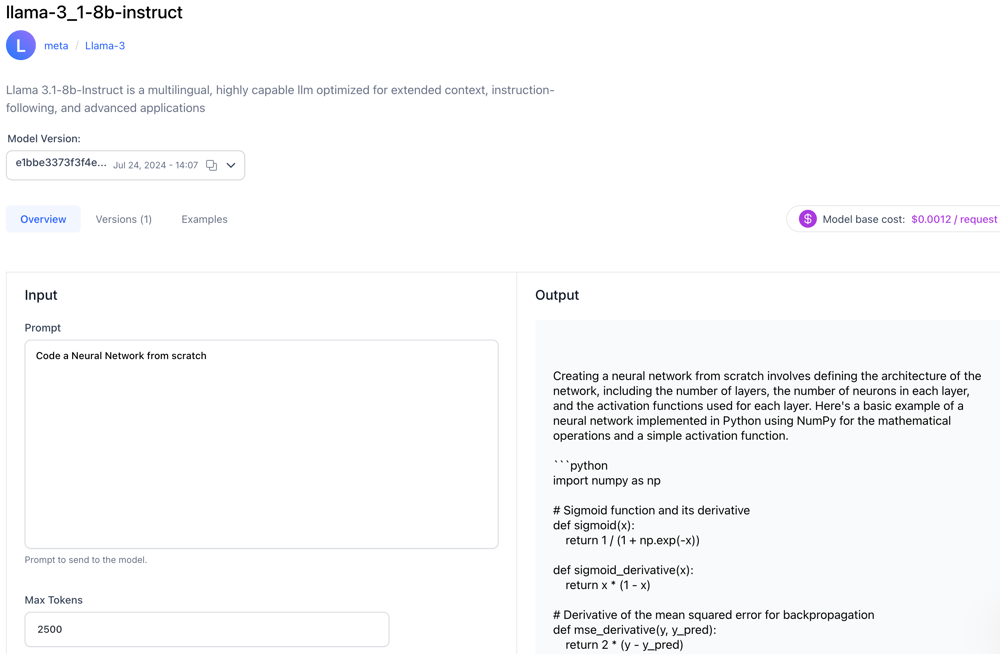
- Published Llama 3.1-8b-Instruct, a multilingual, highly capable LLM optimized for extended context, instruction-following, and advanced applications.
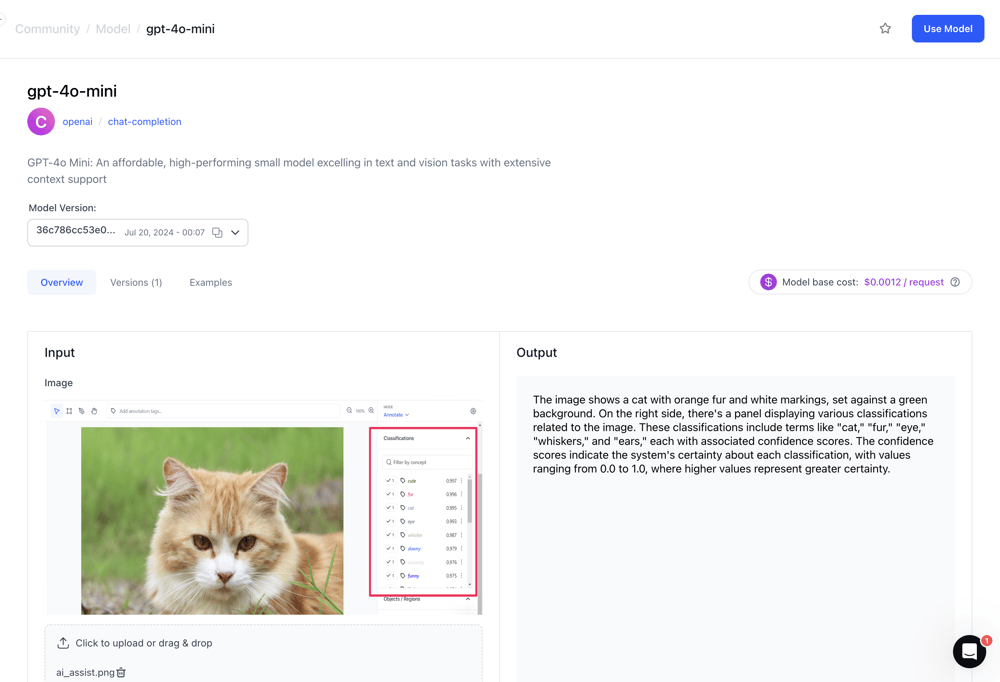
- Published GPT-4o-mini, an affordable, high-performing small model excelling in text and vision tasks with extensive context support.
- Published Qwen1.5-7B-Chat, an open-source, multilingual LLM with 32K token support, excelling in language understanding, alignment with human preferences, and competitive tool-use capabilities.
- Published Qwen2-7B-Instruct, a state-of-the-art multilingual language model with 7.07 billion parameters, excelling in language understanding, generation, coding, and mathematics, and supporting up to 128,000 tokens.
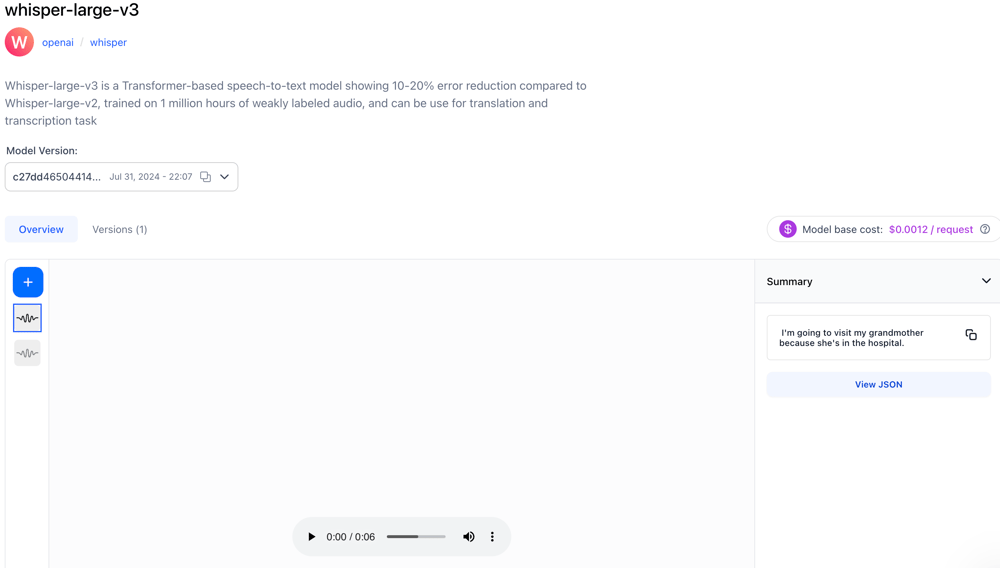
- Published Whisper-Large-v3, a Transformer-based speech-to-text model showing 10-20% error reduction compared to Whisper-Large-v2, trained on 1 million hours of weakly labeled audio, and can be used for translation and transcription tasks.
- Published Llama-3-8b-Instruct-4bit, an instruction-tuned LLM optimized for dialogue use cases. It can outperform many of the available open-source chat LLMs on common industry benchmarks.
- Published Mistral-Nemo-Instruct, a state-of-the-art 12B multilingual LLM with a 128k token context length, optimized for reasoning, code generation, and global applications.
- Published Phi-3-Mini-4K-Instruct, a 3.8B parameter small language model offering state-of-the-art performance in reasoning and instruction-following tasks. It outperforms larger models with its high-quality data training.
Added patch operations – Python SDK
Patch operations have been introduced for apps, datasets, input annotations, and concepts. You can use the Python SDK to either merge, remove, or overwrite your input annotations, datasets, apps, and concepts. All three actions support overwriting by default but have special behavior for lists of objects.
The merge action will overwrite a key:value with key:new_value or append to an existing list of values, merging dictionaries that match by a corresponding id field.
The remove action will overwrite a key:value with key:new_value or delete anything in a list that matches the provided values’ IDs.
The overwrite action will replace the old object with the new object.
Patching App
Below is an example of performing a patch operation on an App. This includes overwriting the base workflow, changing the app to an app template, and updating the app’s description, notes, default language, and image URL. Note that the ‘remove’ action is only used to remove the app’s image.
Patching Dataset
Below is an example of performing a patch operation on a dataset. Similar to the app, you can update the dataset’s description, notes, and image URL.
Patching Input Annotation
Below is an example of doing patch operation of Input Annotations. We have uploaded the image object along with the bounding box annotations and you can change that annotations using the patch operations or remove the annotation.
Patching Concepts
Below is an example of performing a patch operation on concepts. The only supported action currently is overwrite. You can use this to change the existing label names associated with an image.
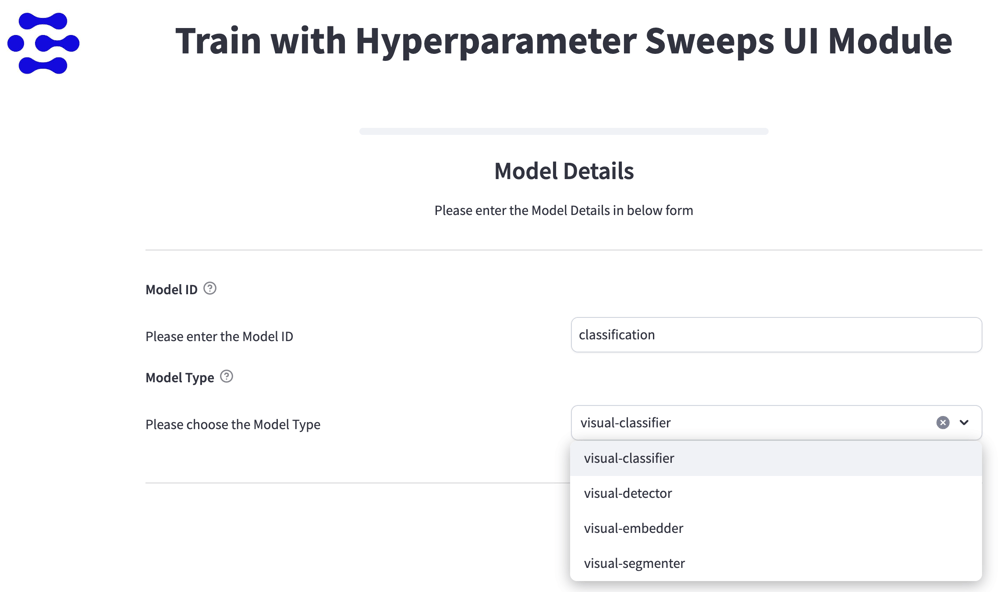
Improved the functionality of the Hyperparamater Sweeps module
Finding the right hyperparameters for training a model can be tricky, requiring multiple iterations to get them just right. The Hyperparameter module simplifies this process by allowing you to test different values and combinations of hyperparameters.
You can now set a range of values for each hyperparameter and decide how much to adjust them with each step. Plus, you can mix and match different hyperparameters to see what works best. This way, you can quickly discover the optimal settings for your model without the need for constant manual adjustments.
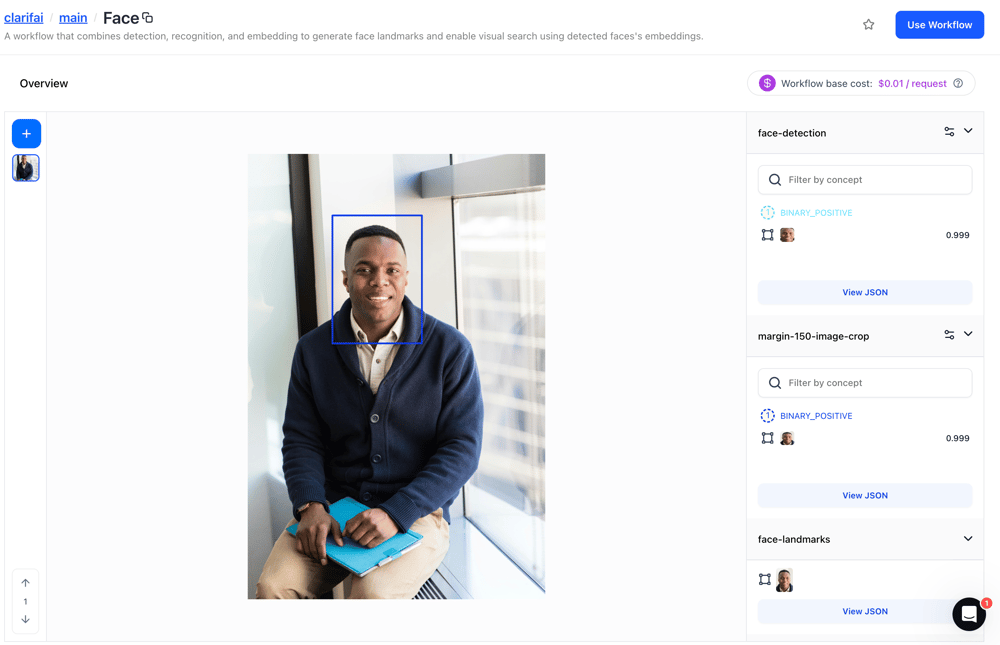
Improved the functionality of the Face workflow
Workflows allows you to combine multiple models to carry out different operations on the Platform. The face workflow combines detection, recognition, and embedding models to generate face landmarks and enable visual search using detected faces’s embeddings.
When you upload an image, the workflow first detects the face and then crops it. Next, it identifies key facial landmarks, such as the eyes and mouth. The image is then aligned using these keypoints. After alignment, it is sent to the visual embedder model, which generates numerical vectors representing each face in the image or video. Finally, these embeddings are used by the face-clustering model to group visually similar faces.
Organization Settings and Management
- Implemented restrictions on the ability to add new organizations based on the user’s current organization count and feature access
- If a user has created one organization and does not have access to the multiple organizations feature, the “Add an organization” button is now disabled. We also display an appropriate tooltip to them.
- If a user has access to the multiple organizations feature but has reached the maximum creation limit of 20 organizations, the “Add an organization” button is disabled. We also display an appropriate tooltip to them.
Additional changes
- We enabled the RAG SDK to use environment variables for enhanced security, flexibility, and simplified configuration management.
- Enabled deletion of associated model assets when removing a model annotation: Now, when you delete a model annotation, the associated model assets are also marked as deleted.
- Fixed issues with Python and Node.js SDK code snippets: If you click the “Use Model” button on an individual model’s page, the “Call by API / Use in a Workflow” modal appears. You can then integrate the displayed code snippets in various programming languages into your own use case.
Previously, the code snippets for Python and Node.js SDKs for image-to-text models incorrectly outputted concepts instead of the expected text. We fixed the issue to ensure the output is now correctly provided as text.
Ready to start building?
Fine-tuning LLMs allows you to tailor a pre-trained large language model to your organization’s unique needs and objectives. With our platform’s no-code experience, you can fine-tune LLMs effortlessly.
Explore our Quickstart tutorial for step-by-step guidance to fine-tune Llama 3.1. Sign up here to get started!
Thanks for reading, see you next time 👋!