
In the digital age, the amount of scholarly articles is growing exponentially. In the Open Research Knowledge Graph’s question-answering facility ASK, for example, more than 80 million research articles have already been indexed. Finding the most relevant information from vast collections of scholarly data can be daunting for researchers, students, and academics. To tackle this challenge, search engines and digital libraries often rely on advanced search techniques, one of the most effective being faceted search.
Faceted search is an advanced search method that allows users to filter and refine search results based on multiple predefined attributes, known as facets. Each facet represents a specific category or attribute of the data, such as the publication year, author, subject area, journal name, or keywords. While faceted search offers significant advantages, traditional faceted search models can still face limitations when applied to large, diverse academic datasets. Often, these models offer static facets that are predefined and do not adapt based on user interactions or the nature of the data being explored. This can lead to an overwhelming or ineffective user experience, especially in environments with vast and rapidly changing datasets like digital libraries and academic search engines.
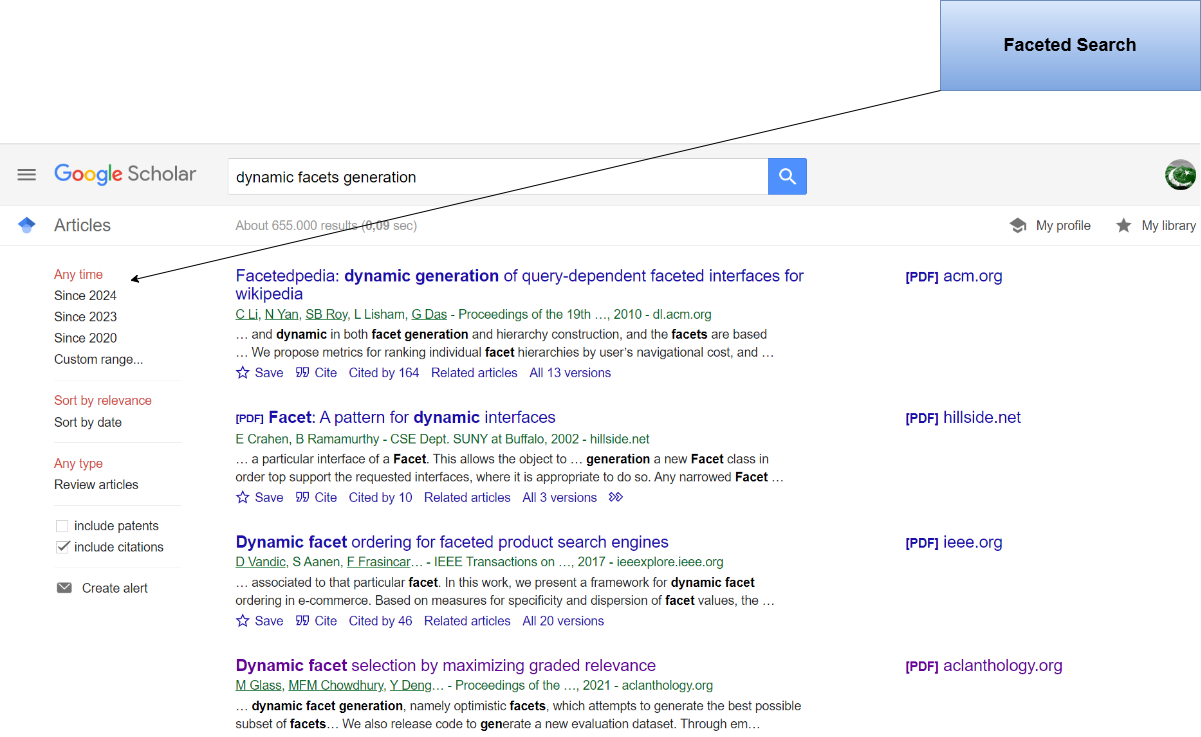 Image 1: Static Faceted Search in Google Scholar.
Image 1: Static Faceted Search in Google Scholar.
This is where dynamic facet generation comes into play. The key innovation behind dynamic facet generation is the ability to adapt and adjust facets in real-time, based on user input and the evolving nature of the dataset. This approach not only makes the search process more flexible and personalized, but also enables a much more efficient and intuitive way to discover relevant academic content.
Our contribution
We developed, proposed, and compared three distinct methods for Dynamic Facet Generation (DFG), each with its unique approach. These methods, depicted in Image 2, include a symbolic approach and two neuro-symbolic approaches that integrate large language models (LLMs) and knowledge bases.
- KB2 (based on Knowledge Bases): KB2 is a symbolic approach that leverages Wikipedia-based knowledge bases to enable dynamic facet generation. In this method, the knowledge base provides structured information that helps in generating facets relevant to the academic content.
- KBLLM (based on a Knowledge Base and a Large Language Model): KBLLM represents a neuro-symbolic approach, combining knowledge bases with the predictive and language-understanding capabilities of an LLM. By blending the structured knowledge of a database with the flexibility of a language model, KBLLM generates facets that are more adaptive to user queries, offering a nuanced, context-aware refinement of search results.
- KBLLMKA (based on a Knowledge Base and a Large Language Model with Knowledge Augmentation): KBLLMKA is an enhanced version of KBLLM that integrates knowledge augmentation to further improve the LLM’s facet predictions. This augmentation provides additional context and relationships from the knowledge base, thereby refining the LLM’s understanding and facet-generation capabilities.
Image 2: Overview diagram illustrating our methodology and the three distinct approaches KB2, KBLLM, and KBLLMKA.
Evaluation
To evaluate the effectiveness of the three proposed Dynamic Facet Generation (DFG) methods—KB2, KBLLM, and KBLLMKA—we tested them on 26 distinct sets of research articles from a variety of academic fields (‘Arts and Humanities’, ‘Engineering’, ‘Life Sciences’, ‘Physical Sciences & Mathematics’, and ‘Social and Behavioral Sciences’). Each set contained an average of 9 papers. This diverse selection allowed us to assess each method’s adaptability and accuracy across a wide range of research domains. Our evaluation combined two key metrics: user ratings from a survey-based assessment and average time taken for dynamic facet generation. KBLLM takes the lead as it achieved 7.2/10 rating, with an average time of 7.9 seconds for DFG, enhancing the overall user experience by providing quick, responsive filtering.
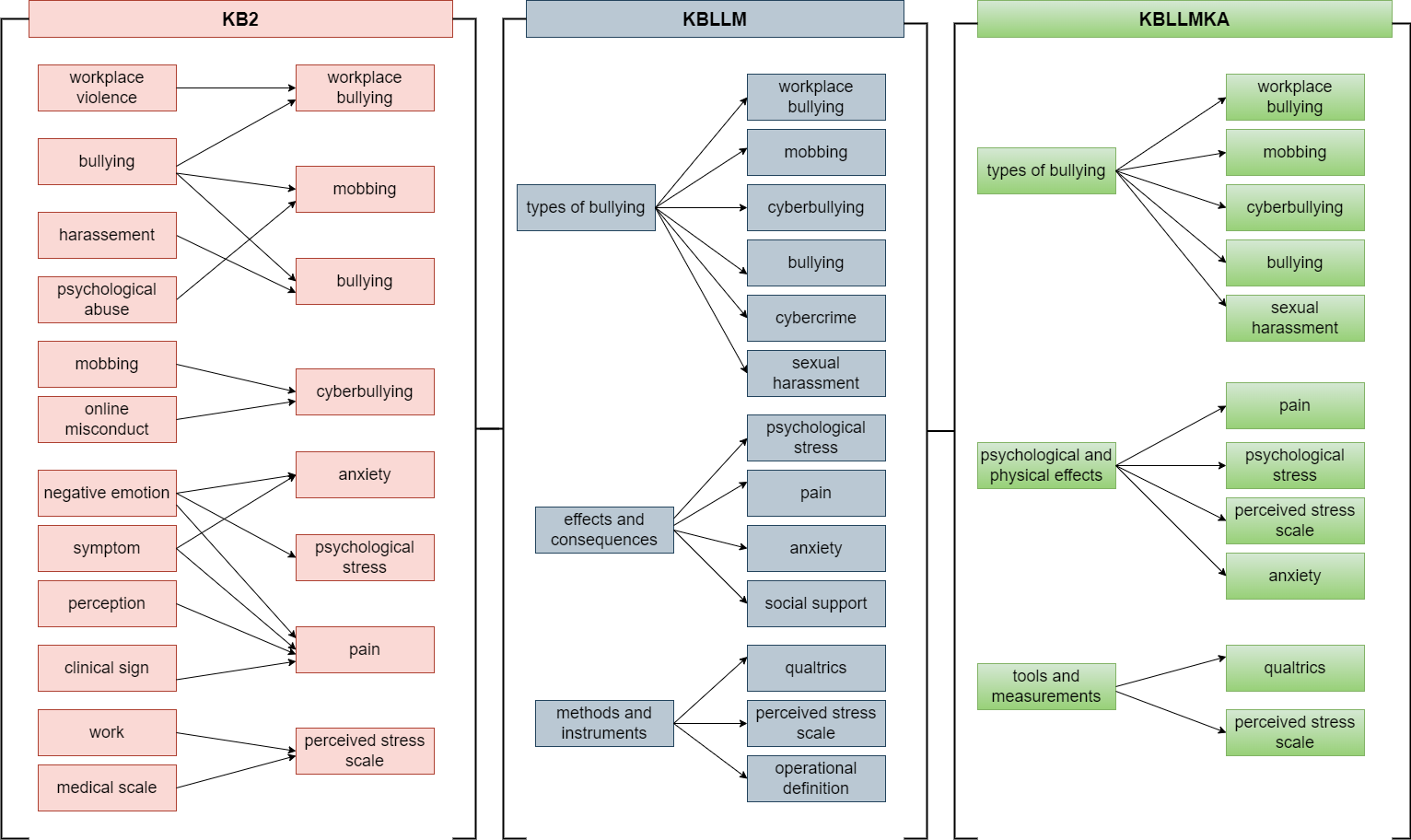 Image 3: Top-n facets generated using KB2, KBLLM, and KBLLMKA facet generation methods for literature on ‘Academic bullying evidence’.
Image 3: Top-n facets generated using KB2, KBLLM, and KBLLMKA facet generation methods for literature on ‘Academic bullying evidence’.
Benefits for Academic Search Engines
Implementing the KBLLM approach to Dynamic Facet Generation (DFG) offers significant benefits for digital libraries. With KBLLM’s ability to dynamically generate and adapt facets in response to user inputs, digital libraries can provide a much more intuitive and efficient search experience for researchers, students, and academics. By integrating the flexibility of a large language model with structured knowledge from established databases, KBLLM creates contextually relevant and adaptive filters that guide users through complex datasets. This makes it easier for users to quickly identify relevant publications, refine search queries, and explore related areas within large collections of research material. Currently, we are integrating the approach into the Open Research Knowledge Graph’s ASK question answering service, allowing users to ask research questions against roughly 80 million academic articles.
Acknowledgements
This work was co-funded by the European Research Council for the project ScienceGRAPH (Grant agreement ID: 819536) as well as the NFDI4Ing project funded by the German Research Foundation (project number 442146713) and NFDI4DataScience (project number 460234259).
This work was accepted at the 27th European Conference on Artificial Intelligence (ECAI 2024).
tags: ECAI, ECAI2024

Mutahira Khalid
is a Research Assistant at the Knowledge Infrastructures Lab at TIB – Leibniz Information Centre for Science and Technology
Mutahira Khalid
is a Research Assistant at the Knowledge Infrastructures Lab at TIB – Leibniz Information Centre for Science and Technology

Sören Auer
is Professor of Data Science and Digital Libraries at Leibniz Universität Hannover and Director of the TIB
Sören Auer
is Professor of Data Science and Digital Libraries at Leibniz Universität Hannover and Director of the TIB

Markus Stocker
leads the Lab Knowledge Infrastructures at the TIB – Leibniz Information Centre for Science and Technology
Markus Stocker
leads the Lab Knowledge Infrastructures at the TIB – Leibniz Information Centre for Science and Technology