Language models (LMs) are advancing as tools for solving problems and as creators of synthetic data, playing a crucial role in enhancing AI capabilities. Synthetic data complements or replaces traditional manual annotation, offering scalable solutions for training models in domains such as mathematics, coding, and instruction-following. The ability of LMs to generate high-quality datasets ensures better task generalization, positioning them as versatile assets in modern AI research and applications.
A significant challenge is assessing which LMs perform better as synthetic data generators. With varied capabilities across proprietary and open-source models, researchers face difficulty selecting appropriate LMs for specific tasks. This complexity stems from the need for a unified benchmark to evaluate these models systematically. Furthermore, while some models excel in problem-solving, this ability only sometimes correlates with their data generation performance, making direct comparisons even more difficult.

Several approaches to synthetic data generation have been explored, using LMs like GPT-3, Claude-3.5, and Llama-based architectures. Methods such as instruction-following, response generation, and quality enhancement have been tested, with varying success across tasks. However, the absence of controlled experimental setups has led to inconsistent findings, preventing researchers from deriving meaningful conclusions about the comparative strengths of these models.
Researchers from institutions like Carnegie Mellon University, KAIST AI, the University of Washington, NEC Laboratories Europe, and Ss. Cyril and Methodius University of Skopje developed the AGORABENCH. This benchmark enables systematic evaluation of LMs as data generators under controlled conditions. AGORABENCH facilitates direct comparisons across tasks, including instance generation, response generation, and quality enhancement by standardizing variables like seed datasets, meta-prompts, and evaluation metrics. The project also collaborates with companies such as NEC Laboratories Europe, leveraging diverse expertise to ensure robustness.
AGORABENCH uses a fixed methodology to evaluate data generation capabilities. It employs specific seed datasets for each domain, such as GSM8K for mathematics and MBPP for coding, ensuring consistency across experiments. Meta-prompts are designed to guide models in generating synthetic data, while variables like instruction difficulty and response quality are assessed using intrinsic metrics. A key metric, Performance Gap Recovered (PGR), quantifies the improvement of student models trained on synthetic data compared to their baseline performance. Principal component analysis (PCA) further identifies factors influencing data generation success, such as instruction diversity and response perplexity.
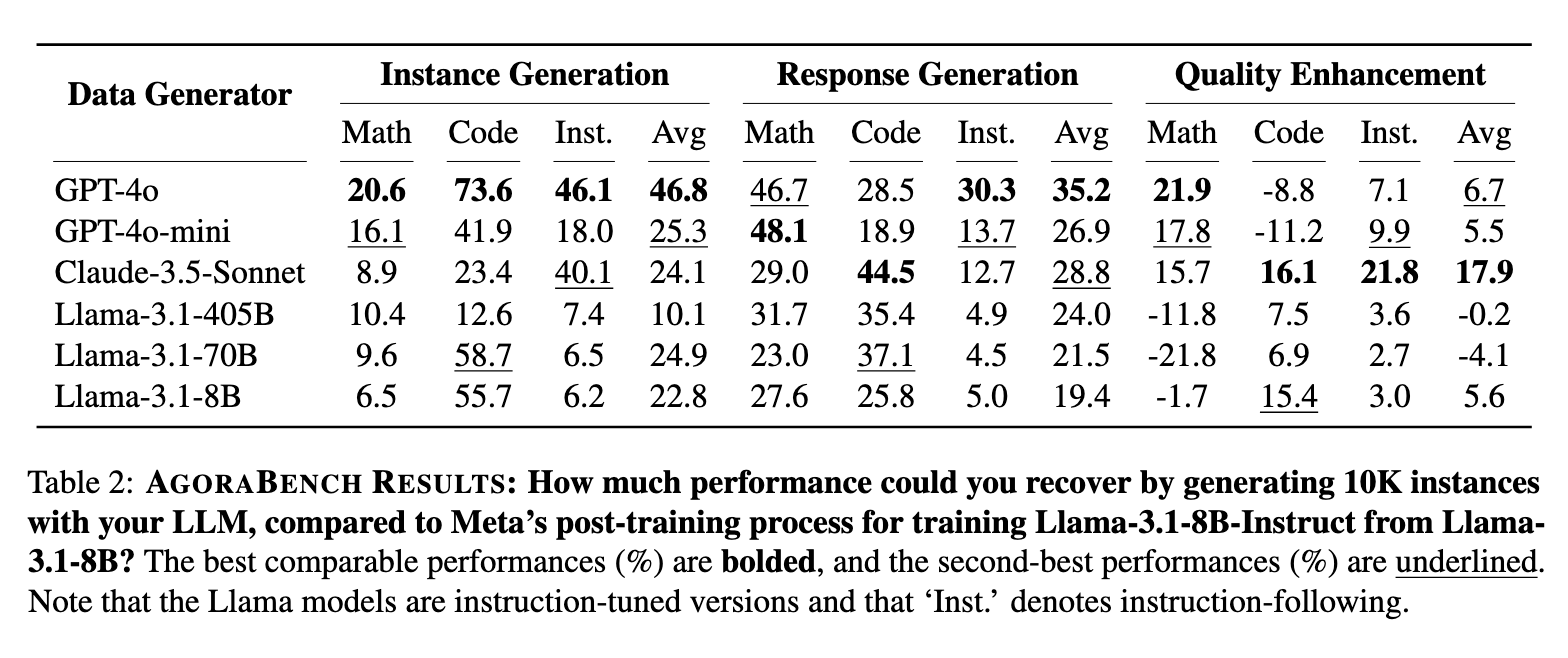
The results from AGORABENCH revealed noteworthy trends. GPT-4o emerged as the top-performing model in instance generation, achieving an average PGR of 46.8% across tasks and excelling in mathematics with a PGR of 20.6%. In contrast, Claude-3.5-Sonnet demonstrated superior performance in quality enhancement, with a PGR of 17.9% overall and 21.8% in coding tasks. Interestingly, weaker models occasionally outperformed stronger ones in specific scenarios. For instance, Llama-3.1-8B achieved a PGR of 55.7% in coding instance generation, surpassing more advanced models like GPT-4o. Cost analysis revealed that generating 50,000 instances with a less expensive model like GPT-4o-mini yielded comparable or better results than 10,000 instances generated by GPT-4o, highlighting the importance of budget-conscious strategies.
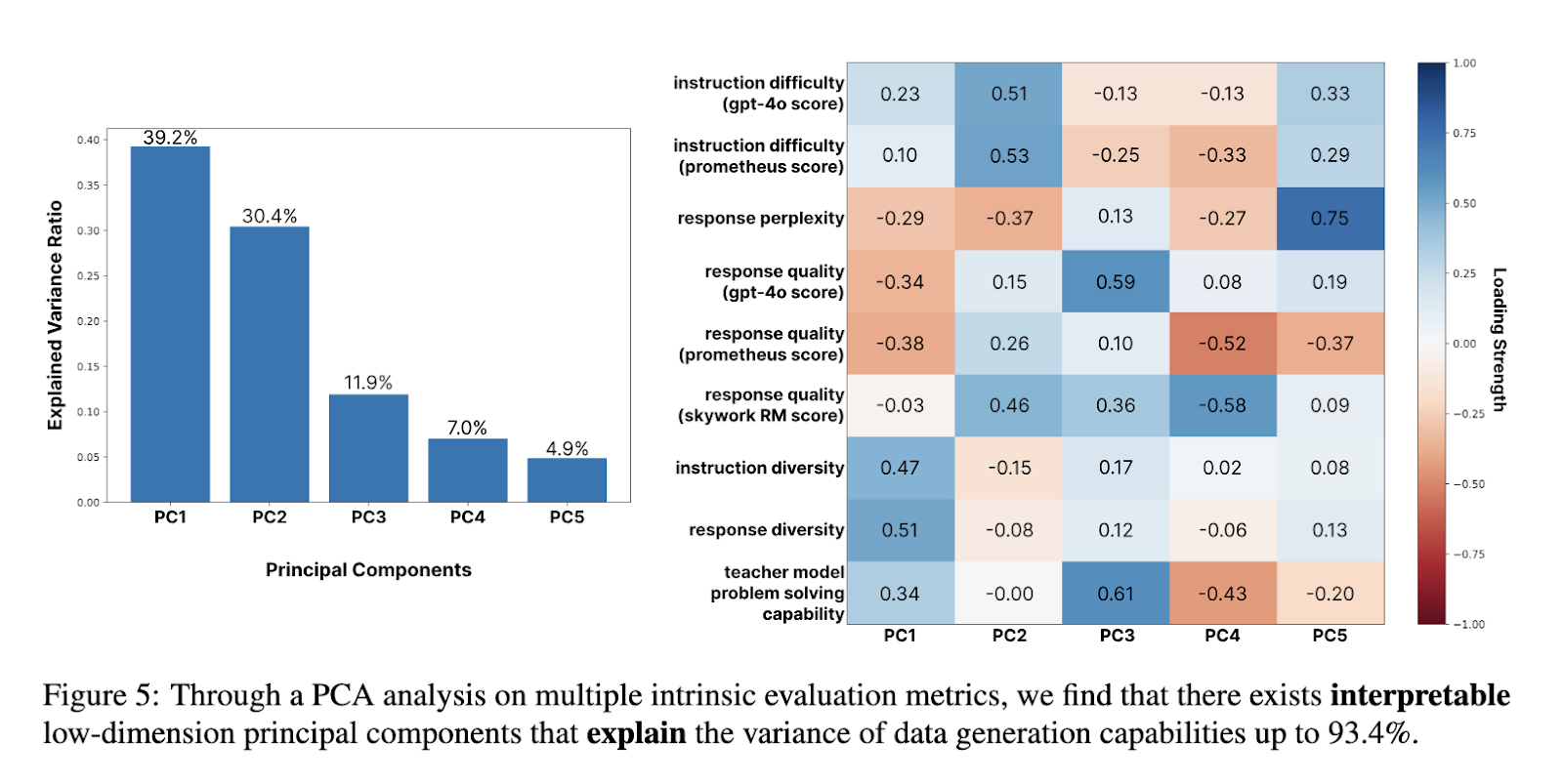
The study underscores the complex relationship between problem-solving and data generation abilities. While stronger problem-solving models do not always produce better synthetic data, intrinsic properties like response quality and instruction difficulty significantly influence outcomes. For example, models with high response quality scores aligned better with task requirements, improving student model performance. The PCA analysis of AGORABENCH data explained 93.4% of the PGR results variance, emphasizing intrinsic metrics’ role in predicting data generation success.
By introducing AGORABENCH, the researchers provide a robust framework for evaluating LMs’ data generation capabilities. The findings guide researchers and practitioners in selecting suitable models for synthetic data generation while optimizing costs and performance. This benchmark also lays the foundation for developing specialized LMs tailored for data generation tasks, expanding the scope of their applications in AI research and industry.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
🚨 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.