Web-crawled image-text datasets are critical for training vision-language models, enabling advancements in tasks such as image captioning and visual question answering. However, these datasets often suffer from noise and low quality, with inconsistent associations between images and text that limit the capabilities of the models. This limitation prevents achieving strong and accurate results, particularly in cross-modal retrieval tasks. Moreover, the computational costs of handling such large datasets are very prohibitive, making it very important to have a better methodology for training.
To address these limitations, researchers have explored synthetic captions generated by multimodal large language models (MLLMs) as replacements for raw web-crawled captions. Synthetic captions improve models’ performance, such as that demonstrated by VeCLIP and Recap-DataComp-1B. Still, current approaches face significant problems: the computational costs for processing whole captions, the issue of scalability especially with complex architectures, and inefficiency in making use of the entire information in synthetic captions.
Researchers from UC Santa Cruz and the University of Edinburgh introduce CLIPS, an enhanced vision-language training framework that maximizes the utility of synthetic captions through two innovative designs. It uses a strategy that focuses on partial synthetic captions for contrastive learning. Through the sampling of a part of synthetic captions, CLIPS shortens the input token length while either improving or retaining performance, consistent with principles derived from the inverse scaling law observed during CLIP training. This methodology not only improves retrieval accuracy but also significantly reduces computational costs. In addition, CLIPS incorporates an autoregressive caption generator that generates whole synthetic captions based on web-crawled captions and their corresponding images. This method follows the recaptioning mechanism found in MLLMs and ensures that synthetically captioned content is well utilized, enriching the semantic alignment between image and text.

The technical implementation involves preprocessing synthetic captions using a sub-caption masking strategy, retaining approximately 32 tokens—about one or two sentences—for the text encoder. This approach is coupled with a multi-positive contrastive loss, aligning both original and shortened captions for improved efficiency and effectiveness. In parallel, the generative framework uses an autoregressive decoder that takes web-crawled image attributes and captions as input, guided by a specially designed combination mask to allow for optimal token interaction. The decoder produces outputs that align with complete synthetic captions, and this training is consistent with using a generative loss function. This training is carried out on extensive datasets like DataComp-1B, and evaluations are made against benchmarks like MSCOCO and Flickr30K. Performance metrics include recall at 1 (R@1) for retrieval tasks and zero-shot classification accuracy.

Evaluations show that CLIPS achieves state-of-the-art performance on a range of tasks. For MSCOCO, it achieves an improvement of more than 5% in text-to-image retrieval accuracy and more than 3% in image-to-text retrieval compared to previous approaches. Similarly, on Flickr30K, the model shows better retrieval accuracy in both directions compared to competing frameworks. The effectiveness of this framework is further emphasized by its scalability, where smaller models trained using CLIPS outperform larger models obtained from competing approaches. In addition to retrieval tasks, the incorporation of the CLIPS visual encoder within multimodal large language models markedly improves their efficacy across various benchmarks, highlighting the flexibility and adaptability of this training framework. Moreover, ablation studies provide further corroboration of the generative modeling method’s effectiveness, demonstrating significant improvements in both alignment and retrieval metrics while preserving computational efficiency.
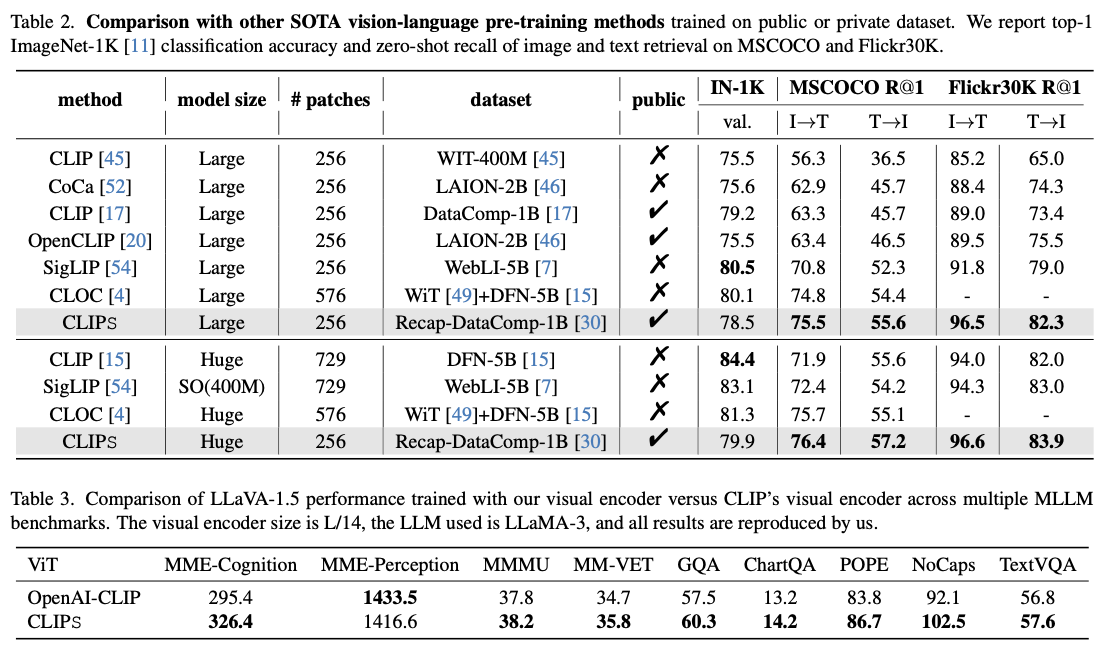
In conclusion, CLIPS transforms vision-language training over the challenges of previous attempts. It establishes new high benchmarks in cross-modal retrieval tasks by using synthetic captions and novel learning methodologies, providing scalability, computational efficacy, and improved multimodal understanding. This framework works as a major step that has been taken in attempting to pursue artificial intelligence through multimodal applications.
Check out the Paper, Code, and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.