
Introduction
Large Language Models (LLMs), no matter how advanced or powerful, fundamentally operate as next-token predictors. One well-known limitation of these models is their tendency to hallucinate, generating information that may sound plausible but is factually incorrect. In this blog, we will –
- dive into the concept of hallucinations,
- explore the different types of hallucinations that can occur,
- understand why they arise in the first place,
- discuss how to detect and assess when a model is hallucinating, and
- provide some practical strategies to mitigate these issues.
What are LLM Hallucinations?
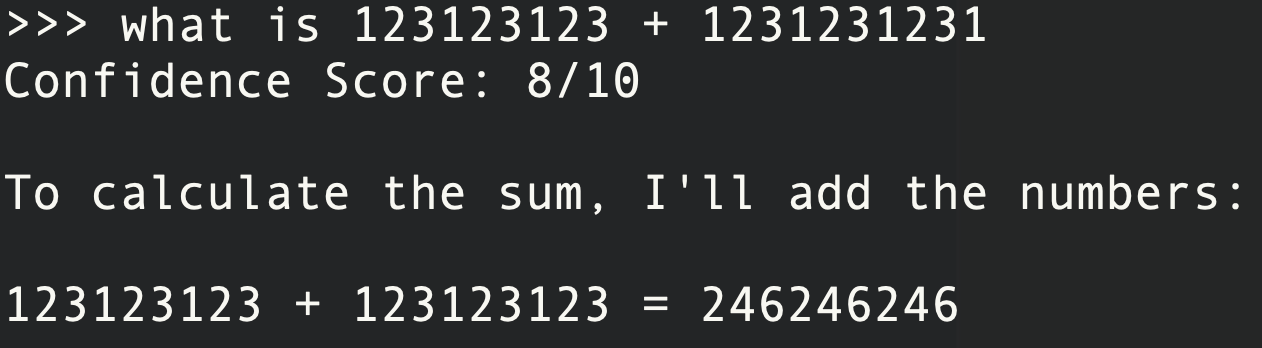
Hallucinations refer to instances where a model generates content that is incorrect and is not logically aligning with the provided input/context or underlying data. For example –
These hallucinations are often categorized based on their causes or manifestations. Here are common taxonomies and a discussion of categories with examples in each taxonomy –
Types of Hallucinations
Intrinsic Hallucinations:
Intrinsic Hallucinations:
These occur when it’s possible to identify the model’s hallucinations solely by comparing the input with the output. No external information is required to spot the errors. Example –
- Producing information in a document extraction task that doesn’t exist in the original document.
- Automatically agreeing with users’ incorrect or harmful opinions, even when they are factually wrong or malicious.
Extrinsic Hallucinations:
These happen when external information is required to evaluate whether the model is hallucinating, as the errors aren’t obvious based only on the input and output. These are usually harder to detect without domain knowledge
Modes of Hallucinations
Factual Hallucinations:
These occur when the model generates incorrect factual information, such as inaccurate historical events, false statistics, or wrong names. Essentially, the LLM is fabricating facts, a.k.a. lying.
A well-known example is the infamous Bard incident –

Here are some more examples of factual hallucinations –
- Mathematical errors and miscalculations.
- Fabricating citations, case studies, or research references out of nowhere.
- Confusing entities across different cultures, leading to “cultural hallucinations.”
- Providing incorrect instructions in response to how-to queries.
- Failing to structure complex, multi-step reasoning tasks properly, leading to fragmented or illogical conclusions.
- Misinterpreting relationships between different entities.
Contextual Hallucinations:
These arise when the model adds irrelevant details or misinterprets the context of a prompt. While less harmful than factual hallucinations, these responses are still unhelpful or misleading to users.
Here are some examples that fall under this category –
- When asked about engine repair, the model unnecessarily delves into the history of automobiles.
- Providing long, irrelevant code snippets or background information when the user requests a simple solution.
- Offering unrelated citations, metaphors, or analogies that do not fit the context.
- Being overly cautious and refusing to answer a normal prompt due to misinterpreting it as harmful (a form of censorship-based hallucination).
- Repetitive outputs that unnecessarily prolong the response.
- Displaying biases, particularly in politically or morally sensitive topics.
Omission-Based Hallucinations:
These occur when the model leaves out crucial information, leading to incomplete or misleading answers. This can be particularly dangerous, as users may be left with false confidence or insufficient knowledge. It often forces users to rephrase or refine their prompts to get a complete response.
Examples:
- Failing to provide counterarguments when generating argumentative or opinion-based content.
- Neglecting to mention side effects when discussing the uses of a medication.
- Omitting drawbacks or limitations when summarizing research experiments.
- Skewing coverage of historical or news events by presenting only one side of the argument.
In the next section we’ll discuss why LLMs hallucinate to begin with.
Reasons for Hallucinations
Bad Training Data
Like mentioned at the beginning of the article, LLMs have basically one job – given the current sequence of words, predict the next word. So it should come as no surprise that if we teach the LLM on bad sequences it will perform badly.
The quality of the training data plays a critical role in how well an LLM performs. LLMs are often trained on massive datasets scraped from the web, which includes both verified and unverified sources. When a significant portion of the training data consists of unreliable or false information, the model can reproduce this misinformation in its outputs, leading to hallucinations.
Examples of poor training data include:
- Outdated or inaccurate information.
- Data that is overly specific to a particular context and not generalizable.
- Data with significant gaps, leading to models making inferences that may be false.
Bias in Training Data
Models can hallucinate due to inherent biases in the data they were trained on. If the training data over-represents certain viewpoints, cultures, or perspectives, the model might generate biased or incorrect responses in an attempt to align with the skewed data.
Bad Training Schemes
The approach taken during training, including optimization techniques and parameter tuning, can directly influence hallucination rates. Poor training strategies can introduce or exacerbate hallucinations, even if the training data itself is of good quality.
- High Temperatures During Training – Training models with higher temperatures encourages the model to generate more diverse outputs. While this increases creativity and variety, it also increases the risk of generating highly inaccurate or nonsensical responses.
- Excessive on Teacher Forcing – Teacher forcing is a method where the correct answer is provided as input at each time step during training. Over-reliance on this technique can lead to hallucinations, as the model becomes overly reliant on perfect conditions during training and fails to generalize well to real-world scenarios where such guidance is absent.
- Overfitting on Training Data – Overfitting occurs when the model learns to memorize the training data rather than generalize from it. This leads to hallucinations, especially when the model is faced with unfamiliar data or questions outside its training set. The model may “hallucinate” by confidently generating responses based on irrelevant or incomplete data patterns.
- Lack of Adequate Fine-Tuning – If a model is not fine-tuned for specific use cases or domains, it will likely hallucinate when queried with domain-specific questions. For example, a general-purpose model may struggle when asked highly specialized medical or legal questions without additional training in those areas.
Bad Prompting
The quality of the prompt provided to an LLM can significantly affect its performance. Poorly structured or ambiguous prompts can lead the model to generate responses that are irrelevant or incorrect. Examples of bad prompts include:
- Vague or unclear prompts: Asking broad or ambiguous questions such as, “Tell me everything about physics,” can cause the model to “hallucinate” by generating (incidentally) unnecessary (to you) information.
- Under-specified prompts: Failing to provide enough context, such as asking, “How does it work?” without specifying what “it” refers to, can result in hallucinated responses that try to fill in the gaps inaccurately.
- Compound questions: Asking multi-part or complex questions in one prompt can confuse the model, causing it to generate unrelated or partially incorrect answers.
Using Contextually Inaccurate LLMs
The underlying architecture or pre-training data of the LLM can also be a source of hallucinations. Not all LLMs are built to handle specific domain knowledge effectively. For instance, if an LLM is trained on general data from sources like the internet but is then asked domain-specific questions in fields like law, medicine, or finance, it may hallucinate due to a lack of relevant knowledge.
In conclusion, hallucinations in LLMs are often the result of a combination of factors related to data quality, training methodologies, prompt formulation, and the capabilities of the model itself. By improving training schemes, curating high-quality training data, and using precise prompts, many of these issues can be mitigated.
How to tell if your LLM is Hallucinating?
Human in the Loop
When the amount of data to evaluate is limited or manageable, it’s possible to manually review the responses generated by the LLM and assess whether it is hallucinating or providing incorrect information. In theory, this hands-on approach is one of the most reliable ways to evaluate an LLM’s performance. However, this method is constrained by two significant factors: the time required to thoroughly examine the data and the expertise of the person performing the evaluation.
Evaluating LLMs Using Standard Benchmarks
In cases where the data is relatively simple and any hallucinations are likely to be intrinsic/limited to the question+answer context, several metrics can be used to compare the output with the desired input, ensuring the LLM isn’t generating unexpected or irrelevant information.
Basic Scoring Metrics: Metrics like ROUGE, BLEU, and METEOR serve as useful starting points for comparison, although they are often not comprehensive enough on their own.
PARENT-T: A metric designed to account for the alignment between output and input in more structured tasks.
Knowledge F1: Measures the factual consistency of the LLM’s output against known information.
Bag of Vectors Sentence Similarity: A more sophisticated metric for comparing the semantic similarity of input and output.
While the methodology is straightforward and computationally cheap, there are associated drawbacks –
Proxy for Model Performance: These benchmarks serve as proxies for assessing an LLM’s capabilities, but there is no guarantee they will accurately reflect performance on your specific data.
Dataset Limitations: Benchmarks often prioritize specific types of datasets, making them less adaptable to varied or complex data scenarios.
Data Leakage: Given that LLMs are trained on vast amounts of data sourced from the internet, there’s a possibility that some benchmarks may already be present in the training data, affecting the evaluation’s objectivity.
Nonetheless, using standard statistical techniques offers a useful but imperfect approach to evaluating LLMs, particularly for more specialized or unique datasets.
Model-Based Metrics
For more complex and nuanced evaluations, model-based techniques involve auxiliary models or methods to assess syntactic, semantic, and contextual variations in LLM outputs. While immensely useful, these methods come with inherent challenges, especially concerning computational cost and reliance on the correctness of the models used for evaluation. Nonetheless, let’s discuss some of the well known techniques to use LLMs for assessing LLMs
Self-Evaluation:
LLMs can be prompted to assess their own confidence in the answers they generate. For instance, you might instruct an LLM to:
“Provide a confidence score between 0 and 1 for every answer, where 1 indicates high confidence in its accuracy.”
However, this approach has significant flaws, as the LLM may not be aware when it is hallucinating, rendering the confidence scores unreliable.
Generating Multiple Answers:
Another very common approach is to generate multiple answers to the same (or slightly varied) question and check for consistency. Sentence encoders followed by cosine similarity can be used to measure how similar the answers are. This method is particularly effective in scenarios involving mathematical reasoning, but for more generic questions, if the LLM has a bias, all answers could be consistently incorrect. This introduces a key drawback—consistent yet incorrect answers don’t necessarily signal quality.
Quantifying Output Relations:
Information extraction metrics help identify whether the relationships between input, output, and ground truth hold up under scrutiny. This involves using an external LLM to create and compare relational structures from the input and output. For example:
Input: What is the capital of France?
Output: Toulouse is the capital of France.
Ground Truth: Paris is the capital of France.
Ground Truth Relation: (France, Capital, Paris)
Output Relation: (Toulouse, Capital, France)
Match: False
This approach allows for more structured verification of outputs but depends heavily on the model’s ability to correctly identify and match relationships.
Natural Language Entailment (NLE):
NLE involves evaluating the logical relationship between a premise and a hypothesis to determine whether they are in alignment (entailment), contradict one another (contradiction), or are neutral. An external model evaluates whether the generated output aligns with the input. For example:
Premise: The patient was diagnosed with diabetes and prescribed insulin therapy.
LLM Generation 1:
Hypothesis: The patient requires medication to manage blood sugar levels.
Evaluator Output: Entailment.
LLM Generation 2:
Hypothesis: The patient does not need any medication for their condition.
Evaluator Output: Contradiction.
LLM Generation 3:
Hypothesis: The patient may have to make lifestyle changes.
Evaluator Output: Neutral.
This method allows one to judge whether the LLM’s generated outputs are logically consistent with the input. However, it can struggle with more abstract or long-form tasks where entailment may not be as straightforward.
Incorporating model-based metrics such as self-evaluation, multiple answer generation, and relational consistency offers a more nuanced approach, but each has its own challenges, particularly in terms of reliability and context applicability.
Cost is also an important factor in these classes of evaluations since one has to make multiple LLM calls on the same question making the whole pipeline computationally and monetarily expensive. Let’s discuss another class of evaluations that tries to mitigate this cost, by obtaining auxiliary information directly from the generating LLM itself.
Entropy-Based Metrics for Confidence Estimation in LLMs
As deep learning models inherently provide confidence measures in the form of token probabilities (logits), these probabilities can be leveraged to gauge the model’s confidence in various ways. Here are several approaches to using token-level probabilities for evaluating an LLM’s correctness and detecting potential hallucinations.
Using Token Probabilities for Confidence:
A straightforward method involves aggregating token probabilities as a proxy for the model’s overall confidence:
- Mean, max, or min of token probabilities: These values can serve as simple confidence scores, indicating how confident the LLM is in its prediction based on the distribution of token probabilities. For instance, a low minimum probability across tokens may suggest uncertainty or hallucination in parts of the output.
Asking an LLM a Yes/No Question:
After generating an answer, another simple approach is to ask the LLM itself (or another model) to evaluate the correctness of its response. For example:
Method:
- Provide the model with the original question and its generated answer.
- Ask a follow-up question, “Is this answer correct? Yes or No.”
- Analyze the logits for the “Yes” and “No” tokens and compute the likelihood that the model believes its answer is correct.
The probability of correctness is then calculated as:
Example:
- Q: “Which programming language is primarily used for iOS app development?”
- A: “Swift” → P(Correct) = 85%
- A: “Objective-C” → P(Correct) = 70%
- A: “Java” → P(Correct) = 10%
- A: “Python” → P(Correct) = 2%
A low P(Correct) value would indicate that the LLM is likely hallucinating.
Training a Separate Classifier for Correctness:
You can train a binary classifier specifically to determine whether a generated response is correct or incorrect. The classifier is fed examples of correct and incorrect responses and, once trained, can output a confidence score for the accuracy of any new LLM-generated answer. While effective, this method requires labeled training data with positive (correct) and negative (incorrect) samples to function accurately.
Fine-Tuning the LLM with an Additional Confidence Head:
Another approach is to fine-tune the LLM by introducing an extra output layer/token that specifically predicts how confident the model is about each generated response. This can be achieved by adding an “I-KNOW” token to the LLM architecture, which indicates the model’s confidence level in its response. However, training this architecture requires a balanced dataset containing both positive and negative examples to teach the model when it knows an answer and when it does not.
Computing token Relevance and Importance:
The “Shifting Attention to Relevance” (SAR) technique involves two key factors:
- Model’s confidence in predicting a specific word: This comes from the model’s token probabilities.
- Importance of the word in the sentence: This is a measure of how critical each word is to the overall meaning of the sentence.
Where importance of a word is calculated by comparing the similarity of original sentence with sentence where the the word is removed.
For example, we know that the meaning of the sentence “of an object” is completely different from the meaning of “Density of an object”. This implies that the importance of the word “Density” in the sentence is very high. We can’t say the same for “an” since “Density of an object” and “Density of object” convey similar meaning.
Mathematically it is computed as follows –
SAR quantifies uncertainty by combining these factors, and the paper calls this “Uncertainty Quantification.”
Consider the sentence: “Density of an object.”. One can compute the total uncertainty like so –
| Density | of | an | object | |
|---|---|---|---|---|
| Logit from Cross-Entropy (A) |
0.238 | 6.258 | 0.966 | 0.008 |
| Importance (B) | 0.757 | 0.057 | 0.097 | 0.088 |
| Uncertainty (C = A*B) |
0.180 | 0.356 | 0.093 | 0.001 |
| Total Uncertainty (average of all Cs) |
(0.18+0.35+0.09+0.00)/4 |
This method quantifies how crucial certain words are to the sentence’s meaning and how confidently the model predicts those words. High uncertainty scores signal that the model is less confident in its prediction, which could indicate hallucination.
To conclude, entropy-based methods offer diverse ways to evaluate the confidence of LLM-generated responses. From simple token probability aggregation to more advanced techniques like fine-tuning with additional output layers or using uncertainty quantification (SAR), these methods provide powerful tools to detect potential hallucinations and evaluate correctness.
How to Avoid Hallucinations in LLMs
There are several strategies you can employ to either prevent or minimize hallucinations, each with different levels of effectiveness depending on the model and use case. As we already discussed above, cutting down on the sources of hallucinations by improving the training data quality and training quality can go a long way to reduce hallucinations. Here are some more techniques that can none the less be effective in any situation with any LLM –
1. Provide Better Prompts
One of the simplest yet most effective ways to reduce hallucinations is to craft better, more specific prompts. Ambiguous or open-ended prompts often lead to hallucinated responses because the model tries to “fill in the gaps” with plausible but potentially inaccurate information. By giving clearer instructions, specifying the expected format, and focusing on explicit details, you can guide the model toward more factual and relevant answers.
For example, instead of asking, “What are the benefits of AI?”, you could ask, “What are the top three benefits of AI in healthcare, specifically in diagnostics?” This limits the scope and context, helping the model stay more grounded.
2. Find Better LLMs Using Benchmarks
Choosing the right model for your use case is crucial. Some LLMs are better aligned with particular contexts or datasets than others, and evaluating models using benchmarks tailored to your needs can help find a model with lower hallucination rates.
Metrics such as ROUGE, BLEU, METEOR, and others can be used to evaluate how well models handle specific tasks. This is a straightforward way to filter out the bad LLMs before even attempting to use an LLM.
3. Tune Your Own LLMs
Fine-tuning an LLM on your specific data is another powerful strategy to reduce hallucination. This customization process can be done in various ways:
3.1. Introduce a P(IK) Token (P(I Know))
In this technique, during fine-tuning, you introduce an additional token (P(IK)) that measures how confident the model is about its output. This token is trained on both correct and incorrect answers, but it is specifically designed to calibrate lower confidence when the model produces incorrect answers. By making the model more self-aware of when it doesn’t “know” something, you can reduce overconfident hallucinations and make the LLM more cautious in its predictions.
3.2. Leverage Large LLM Responses to Tune Smaller Models
Another strategy is to use responses generated by massive LLMs (such as GPT-4 or larger proprietary models) to fine-tune smaller, domain-specific models. By using the larger models’ more accurate or thoughtful responses, you can refine the smaller models and teach them to avoid hallucinating within your own datasets. This allows you to balance performance with computational efficiency while benefiting from the robustness of larger models.
4. Create Proxies for LLM Confidence Scores
Measuring the confidence of an LLM can help in identifying hallucinated responses. As outlined in the Entropy-Based Metrics section, one approach is to analyze token probabilities and use these as proxies for how confident the model is in its output. Lower confidence in key tokens or phrases can signal potential hallucinations.
For example, if an LLM assigns unusually low probabilities to critical tokens (e.g., specific factual information), this may indicate that the generated content is uncertain or fabricated. Creating a reliable confidence score can then serve as a guide for further scrutiny of the LLM’s output.
5. Ask for Attributions and Deliberation
Requesting that the LLM provide attributions for its answers is another effective way to reduce hallucinations. When a model is asked to reference specific quotes, resources, or elements from the question or context, it becomes more deliberate and grounded in the provided data. Additionally, asking the model to provide reasoning steps (as in Chain-of-Thought reasoning) forces the model to “think aloud,” which often results in more logical and fact-based responses.
For example, you can instruct the LLM to output answers like:
“Based on X study or Y data, the answer is…” or “The reason this is true is because of Z and A factors.” This method encourages the model to connect its outputs more directly to real information.
6. Provide Likely Options
If possible, constrain the model’s generation process by providing several pre-defined, diverse options. This can be done by generating multiple responses using a higher temperature setting (e.g., temperature = 1 for creative diversity) and then having the model select the most appropriate option from this set. By limiting the number of possible outputs, you reduce the model’s chance to stray into hallucination.
For instance, if you ask the LLM to choose between multiple plausible responses that have already been vetted for accuracy, it’s less likely to generate an unexpected or incorrect output.
7. Use Retrieval-Augmented Generation (RAG) Systems
When applicable, you can leverage Retrieval-Augmented Generation (RAG) systems to enhance context accuracy. In RAG, the model is given access to an external retrieval mechanism, which allows it to pull information from reliable sources like databases, documents, or web resources during the generation process. This significantly reduces the likelihood of hallucinations because the model is not forced to invent information when it doesn’t “know” something—it can look it up instead.
For example, when answering a question, the model could consult a document or knowledge base to fetch relevant facts, ensuring the output remains rooted in reality.
How to Avoid Hallucinations during Document Extraction
Armed with knowledge, one can use the following techniques to avoid hallucinations when dealing with information extraction in documents
- Cross verify responses with document content: The nature of document extraction is such that we are extracting information verbatim. This means, if the model returns something that is not present in the document, then it means the LLM is hallucinating
- Ask the LLM the location of information being extracted: When the questions are more complex, such as second-order information (like sum of all the items in the bill), make the LLM provide the sources from the document as well as their locations so that we can cross check for ourselves that the information it extracted is legitimate
- Verify with templates: One can use functions such as format-check, regex matching to assert that the extracted fields are following a pattern. This is especially useful when the information is dates, amounts or fields that are known to be within a template with prior knowledge.
- Use multiple LLMs to verify: As spoken in above sections, one can use several LLM passes in a myriad of ways to confirm that the response is always consistent, and hence reliable.
- Use model’s logits: One can check the model’s logits/probabilities to come up with a proxy for confidence score on the critical entities.
Conclusion
Hallucinations are bad and inevitable as of 2024. Avoiding them involves a combination of thoughtful prompt design, model selection, fine-tuning, and confidence measurement. By leveraging the strategies mentioned, at any stage of the LLM pipeline—whether it’s during data curation, model selection, training, or prompting—you can significantly reduce the chances of hallucinations and ensure that your LLM produces more accurate and reliable information.